Can semantic keypoints help us improve calibration results?
When we use photogrammetry to recreate a scene in 3D, there are some objects that will recur between projects, such as lamp posts, curbs, or manhole covers. With the right algorithms, it is possible to automatically identify some of the scene elements, which can in turn improve the calibration of the project. This is how we are tailoring our software to suit this.
This article was written with the input and help of Andrea Cimatoribus, a senior research and development engineer at Pix4D.
The background of semantic key points and calibration
The focus here is on semantic key points, which are representative points on a 3D object. A simple way to describe them is as a 3D associated label that is associated with a defined object, such as a fire hydrant or a manhole. They provide a concise abstraction for a variety of visual understanding tasks.

With semantic key points, we can find the key elements of an object - so in a manhole, the center, or on a fire hydrant, the base. The ability to automatically detect some of these points is already present in PIX4Dsurvey, where a complex pipeline runs on the project to identify semantic key points using the calibration output. However, our team knows that semantic key point identification can happen before the calibration step of processing. If the key points were analyzed prior to processing, they could be used to improve the calibration process by creating a tie point for the software to use as a reference point - similar to the manual process with Manual Tie Points (MTPs).
Thus, the challenge was this: to understand if we can identify semantic key points with a sufficient number and quality level to improve calibration results in at least some use cases.
How can semantic key points compare to manual tie points?
We know that the addition of MTPs during the calibration process can substantially improve the results and accuracy of measurements. MTPs are very powerful, but time-consuming: to create them, a person has to click on a key point in several images which can take time and is error-prone.

By investigating a new system that can, at least partially, reduce the manual operations creating MTPs in correspondence with semantic key points, we can reduce the chances of errors and save time.
To do this we would need to set up a series of algorithms that can automatically reproduce what a user would do:
- Extract stable key points from images (e.g. the base of a fire hydrant, the center of a manhole, etc.)
- Mark the same key point in multiple images
- The goal is to verify that an automatic algorithm can: reach enough accuracy in detection to propose useful tie points and remove the need for manual, time-consuming, operations
It became clear that the object detection step on the images should be the focal point for extracting semantic keypoints.
Applying machine learning and computer vision to semantic key points
To test a new system for object detection and semantic key points, we focused on identifying manholes. The ellipse shape of a manhole is fairly uniform between datasets and therefore easy to test across multiple projects.
One option for object detection is to use the Hough transform, which is a feature extraction technique that can be used in image analysis, computer vision, and digital image transformations. However, it can be computationally expensive to implement, so the team chose to look for an alternative that combines geometric property analysis with a Machine Learning algorithm.
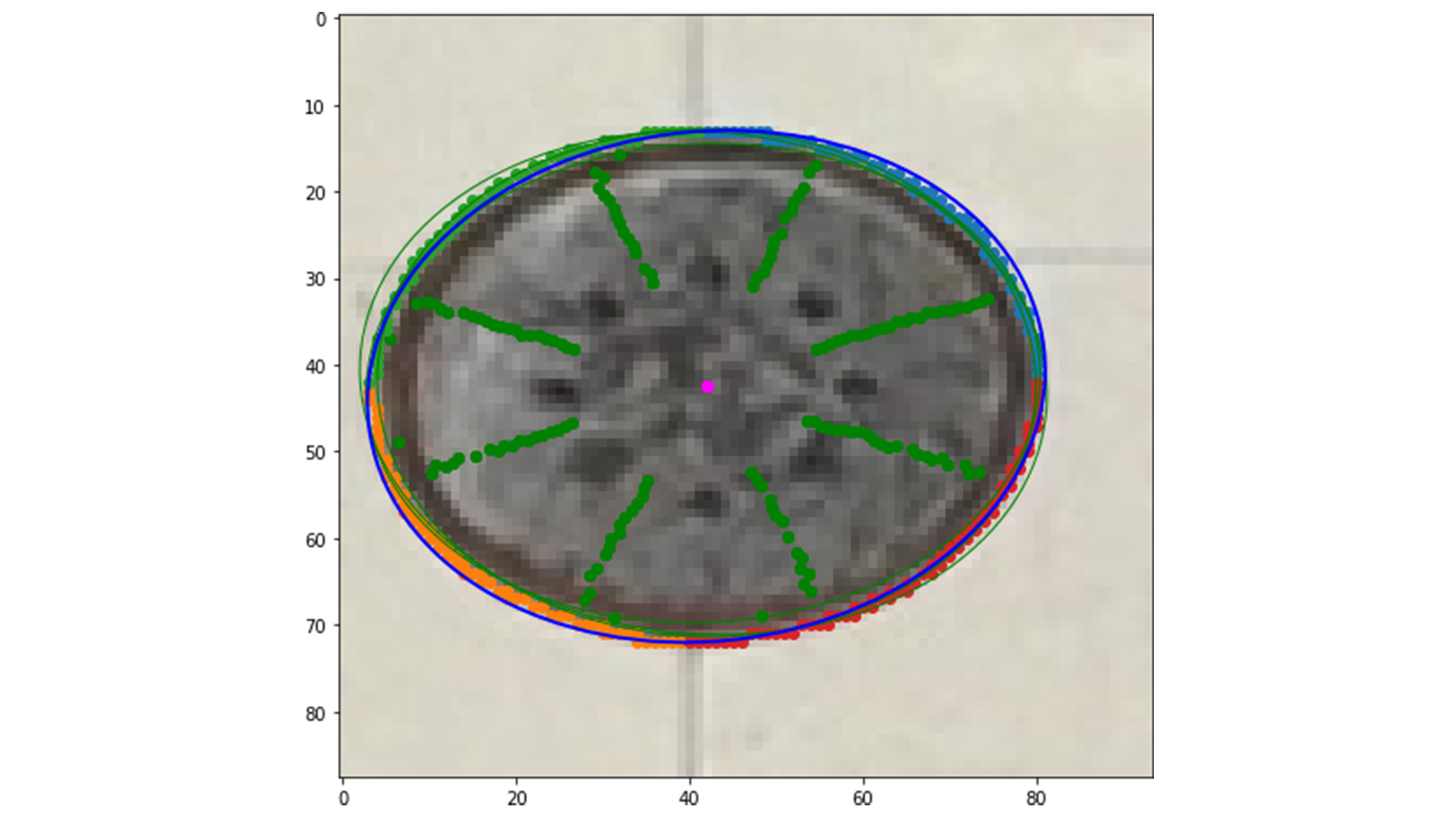
The elliptical shape of manhole covers can be used to identify the center of the cover. With nadir imagery (where a camera points straight down), the ellipse could be identified with a reprojection error of around 0.98 pixels - not perfect, but accurate enough to test the hypothesis of improving calibration. This slight deviation meant that although there was a shift between the ellipse center and the projected circle center, the difference is small enough that the point can still be used as a calibration mark for nadir projects.
With this in mind, the developer team could then start planning how to implement a system that would work regardless of a camera’s pose and be completely automatic. The approach began in three steps. The first was to analyze how the YOLO Deep Learning algorithm (an object detector), looks for bounding boxes in images that contain a manhole. A salient key point (the center of a manhole) is then extracted using traditional computer vision approaches. Finally, a graph analysis algorithm called CLEAR is used to cluster key points on different images together so that all key points referring to the single same real-world object are grouped together.
The CLEAR algorithm is a consistent lifting, embedding, and alignment rectification algorithm that is used to improve the alignment and fusion of observations looking from multiple perspectives. This is ideal for forming additional input to the calibration process by providing MTPs to constrain and refine the calibration in the same way a human would. The algorithm will cluster point detections from the same class, provided they are spaced out and their semantic label is not too common.
Thus, through this system of identifying key points and defining them semantically with a mix of the YOLO and CLEAR algorithms, the process was then tested within the Pix4D processing pipeline. There were multiple examples where the addition of a semantic keypoint acting as a tie point helped to resolve calibration issues where the calibration camera had a larger error in its estimated position. The semantic key points were able to reduce the error margin to an acceptable value.
What comes next?
As a result of this process of researching and testing new algorithms for identifying semantic key points, our team found that semantic understanding of a scene can help calibration in some situations. If and how this is true depends on a combination of factors, including the capture plan, the number, and the location of the extracted semantic key points. The process requires accurate marks through the MTPs which can influence calibration. MTPs are already well regarded and used by Pix4D, but they need to be accurately identified otherwise this can negatively affect the calibration.
Overall, the belief is that by training this model to find specified objects in strategic locations, the semantic key points will be a new part of improving calibration in processing. There needs to be a balance struck between the costs of data preparation and results, and with this new workflow, our team believes they’ve found a realistic new system.
Got questions, or want to get involved? Join the conversation on LinkedIn and follow our hashtag #Pix4DLabs.